PostgreSQL 14 — Streaming replication failover
- Marharyta Kadatska
Since the database is a critical element of Webitel's architecture, we need to take care of data integrity and availability. There are several different options for building a fault-tolerant PostgeSQL cluster using third-party components, but today we will look at building a Warm standby with manual failover.
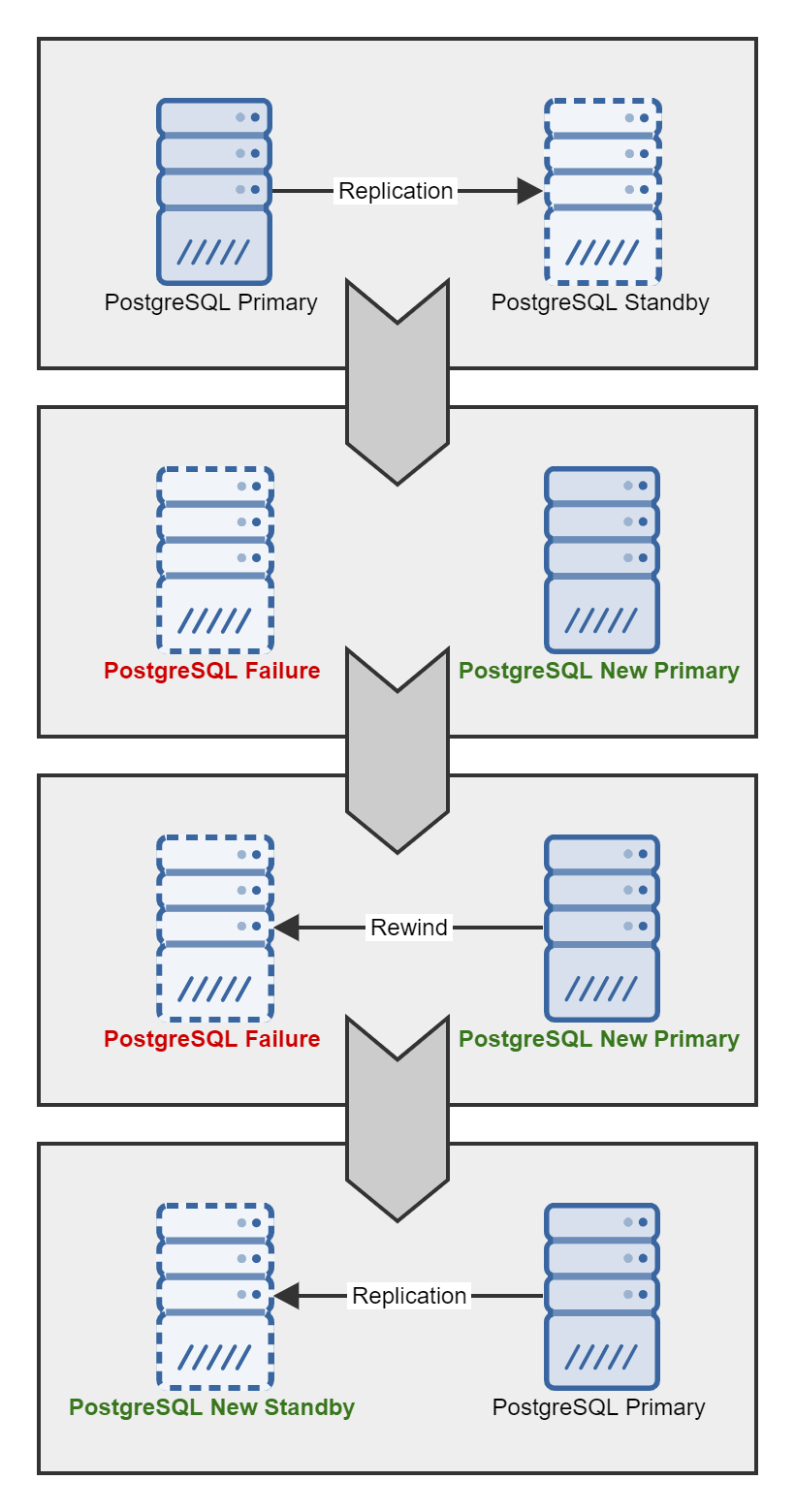
You will find a general setup diagram in this image:
Operating system settings
Created 2 identical virtual machines:
- db-121 with address 10.9.8.121 for the main database
- db-122 with address 10.9.8.122 for secondary database

Please note that it is important that the settings of the servers are the same, otherwise there may be problems with the operation of the replica.
To simplify the connection of our services, I additionally introduce the address 10.9.8.120, which will always be only on the main base (and it will not hurt to add a host in DNS). All services will connect to it. To do this, I set up the network on the main server with Debian Linux:
root@db-121:/ # cat /etc/network/interfaces# The primary network interface
allow-hotplug ens18
iface ens18 inet static
address 10.9.8.121/24
gateway 10.9.8.7
dns-nameservers 1.1.1.1# The floating IP
iface ens18:1 inet static
address 10.9.8.120/24
Та на другому:
root@db-122:/# cat /etc/network/interfaces# The primary network interface
allow-hotplug ens18
iface ens18 inet static
address 10.9.8.122/24
gateway 10.9.8.7
dns-nameservers 1.1.1.1# The floating IP
iface ens18:1 inet static
address 10.9.8.120/24
Basically, I raise the address for connecting services:
root@db-121:/ # ifup ens18:1ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether de:5c:6b:c2:ce:92 brd ff:ff:ff:ff:ff:ff
inet 10.9.8.122/24 brd 10.9.8.255 scope global ens18
valid_lft forever preferred_lft forever
inet 10.9.8.120/24 brd 10.9.8.255 scope global secondary ens18:1
valid_lft forever preferred_lft forever
Database settings
On both servers, install PostgreSQL 14 with all modules as described in our documentation: https://git.webitel.com/projects/WEP/repos/postgres/
Also, do not forget to allow connection from the network:
egrep "^listen" /etc/postgresql/14/main/postgresql.conflisten_addresses = '*' # what IP address(es) to listen on;
/etc/postgresql/14/main/pg_hba.conf
host all all 127.0.0.1/32 scram-sha-256
host all all 10.0.0.0/8 scram-sha-256host replication all 127.0.0.1/32 scram-sha-256
host replication all 10.9.8.0/24 scram-sha-256
Main server - deploy the webitel database schema and create a user for replication:
root@db-121:/ # sudo -u postgres psql -c "CREATE ROLE wbtrepl WITH REPLICATION PASSWORD 'password' LOGIN;"root@db-121:/ # sudo -u postgres psql -c "GRANT EXECUTE ON function pg_catalog.pg_ls_dir(text, boolean, boolean) TO wbtrepl;"root@db-121:/ # sudo -u postgres psql -c "GRANT EXECUTE ON function pg_catalog.pg_stat_file(text, boolean) TO wbtrepl; "root@db-121:/ # sudo -u postgres psql -c "GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text) TO wbtrepl; "root@db-121:/ # sudo -u postgres psql -c "GRANT EXECUTE ON function pg_catalog.pg_read_binary_file(text, bigint, bigint, boolean) TO wbtrepl; "root@db-121:/ # systemctl restart postgresql
The second server - we start the database replication from the main server:
postgres@db-122:~# systemctl stop postgresqlpostgres@db-122:~# sudo -u postgres rm -r /var/lib/postgresql/14/main/*postgres@db-122:~# sudo -u postgres pg_basebackup -h 10.9.8.120 -p 5432 -U wbtrepl -D /var/lib/postgresql/14/main/ -Fp -Xs -R -Ppostgres@db-122:~# systemctl restart postgresql
We got a fully working scheme with a primary and a secondary server. The replica will always have all the relevant data, but will only work in read mode:
postgres@db-122:~# sudo -u postgres psql webitelpsql (14.4 (Debian 14.4-1.pgdg100+1))Type "help" for help.webitel=# update dispatcher set description='FS';ERROR: cannot execute UPDATE in a read-only transaction
Change of main base
Now I shut down the main db-121 server. My next steps are:
- I activate the main IP address on the replica
- I switch the replica to the main base mode
root@db-122:~# ifup ens18:1ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether de:5c:6b:c2:ce:92 brd ff:ff:ff:ff:ff:ff
inet 10.9.8.122/24 brd 10.9.8.255 scope global ens18
valid_lft forever preferred_lft forever
inet 10.9.8.120/24 brd 10.9.8.255 scope global secondary ens18:1
valid_lft forever preferred_lft foreverroot@db-122:~# sudo -u postgres /usr/lib/postgresql/14/bin/pg_ctl promote -D "/etc/postgresql/14/main"root@db-122:~# systemctl restart postgresql
That's it, we can now safely connect to db-122, which is our new primary server. Nothing has changed for all clients, the connection address is still the same 10.9.8.120
Bringing back the old main server
So we got to the point where we got the old main server back up and running. We looked at the logs, understood what exactly was covered, and fixed everything 🔧
Now our task is to turn it into a new replica. We have 2 variations:
- if the database is not very large, it is easier to restart the replica using the pg_basebackup command as described above
- if there is a lot of data, it is easier to use the pg_rewind utility
Since everything is clear with the first option, I will describe the second. An important point, for correct recovery using pg_rewind, you need to enable the parameter wal_log_hints
egrep "^wal_log" /etc/postgresql/14/main/postgresql.confwal_log_hints = on # also do full page writes of non-critical updates
As I read in this article, the option can increase the amount of data transferred over the network and stored on disks. Therefore, if there is an opportunity to restart the replica from "0", restart it 😉
Restoring the old server:
root@db-121:~# systemctl stop postgresqlroot@db-121:~# sudo -u postgres /usr/lib/postgresql/14/bin/pg_rewind -P --target-pgdata="/var/lib/postgresql/14/main" --source-server="host=10.9.8.120 port=5432 user=wbtrepl password=password dbname=webitel"root@db-121:~# sudo -u postgres touch /var/lib/postgresql/14/main/standby.signalroot@db-121:~# systemctl restart postgresql
Everything, now o̶r̶a̶n̶g̶e̶ ̶i̶s̶ ̶t̶h̶e̶ ̶n̶e̶w̶ ̶b̶l̶a̶c̶k̶ old server is a new replica!
Conclusion
You did it - read it! All the examples in this article are completely working, however, these are only examples when you plan to implement your own cluster, then take into account specifically your wishes for the speed of switching in case of failure of the main database. It is possible that only 2 servers will not be enough for you, or you will want to fully automate the switchover with no downtime. In any case, I hope my note serves as an initial guide for you.